

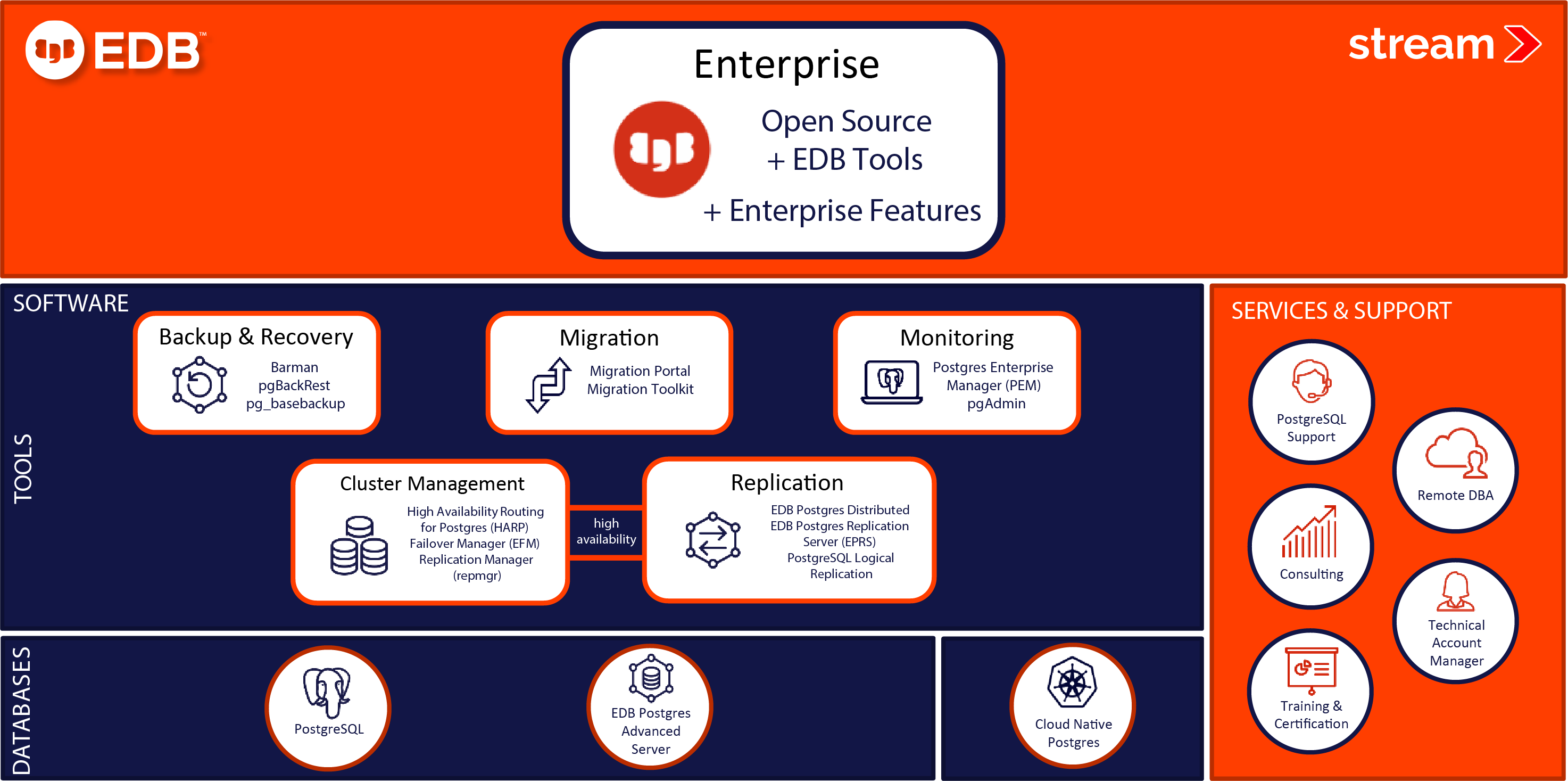
ฐานข้อมูล (Database) ถือเป็นหัวใจสำคัญขององค์กรที่ต้องมีการบริหารจัดการให้มีประสิทธิภาพ ดังนั้นองค์กรส่วนใหญ่จึงมองหาโปรแกรม หรือโซลูชั่นเข้ามาช่วยบริหารจัดการฐานข้อมูล ในปัจจุบันก็มีกระแสที่องค์กรได้เล็งเห็นความสามารถว่า ซอฟต์แวร์โอเพ่นซอร์ส (Open-source Software) ก็ทำงานได้ดีไม่แพ้ซอฟต์แวร์เพื่อการค้า (Commercial License) อีกทั้งยังยืดหยุ่นเปิดกว้างมากกว่า สตรีมฯ จึงขอแนะนำโซลูชั่นที่จะเข้ามาเพิ่มประสิทธิภาพระบบจัดการฐานข้อมูล สามารถดึงข้อมูลมาใช้ได้อย่างรวดเร็วด้วยวิธีการประมวลผลข้อมูลและจัดเก็บในรูปแบบของตารางข้อมูลที่เชื่อมต่อกัน โดยมีระบบ EDB (Enterprise DB) ซึ่งเป็นระบบการจัดการฐานข้อมูลเชิงสัมพันธ์ หรือ RDBMS (Relational Database Management System) เป็นการประมวลผลข้อมูลและจัดเก็บในรูปแบบตารางที่เชื่อมต่อกันจากโค้ดที่ฝังอยู่ในข้อมูล เช่น ข้อมูลเลขที่บัตรประจำตัวประชาชน สามารถดึงข้อมูล ชื่อ ที่อยู่ เบอร์โทรศัพท์ หรือข้อมูลส่วนตัวอื่นๆ ที่กรอกในตอนแรกของการจัดเก็บ นำมาใช้งานได้ ซึ่งเป็นการพัฒนามาจากโอเพ่นซอร์ส ชื่อดังอย่าง PostgreSQL ที่นำมาพัฒนาเพิ่มขีดความสามารถพร้อม Services & Support โดย EDB (Enterprise DB) ที่สำคัญสามารถช่วยลูกค้าลดค่าใช้จ่ายในการจัดหา Commercial License ลงได้เป็นอย่างมาก
ซึ่งปัจจุบันองค์กรทั่วโลกให้การยอมรับ และตื่นตัวกับการแสวงหาโอเพ่นซอร์สเข้ามาใช้งานในองค์กรแทบทุกอย่าง โดยหากพูดถึงประโยชน์นั้นมี 3 ปัจจัยหลักคือ
ปัจจัยแรก การลดต้นทุน เนื่องจากโอเพ่นซอร์สเป็นเรื่องที่ทุกคนสามารถเข้าถึง และนำมาใช้ได้โดยไม่มีค่าใช้จ่าย ซึ่งหากเทียบกับซอฟต์แวร์ที่ผลิตออกมาเพื่อการค้า ในองค์กรที่มักมีมูลค่าหลายล้านหรือหลายสิบล้านก็ถือว่าเป็นการลงทุนที่น่าสนใจ
ปัจจัยที่สอง โอเพ่นซอร์สเปิดกว้าง เผยโค้ดให้เห็นถึงการทำงาน ทำให้ทุกคนสามารถแชร์ความรู้และสร้างการเปลี่ยนแปลงใหม่ได้ กล่าวคือไอเดียจากคนจำนวนมากย่อมดีกว่าซอฟต์แวร์ทางการค้าที่สร้างโดยบุคคลไม่กี่คน ซึ่งนอกจากเรื่องฟีเจอร์แล้วความเปิดกว้างนี้ยังส่งผลไปถึงเรื่อง Security ที่เปิดให้ทุกคนรีวิวได้อย่างโปร่งใส ลดโอกาสเกิดช่องโหว่
ปัจจัยสุดท้าย โอเพ่นซอร์สถือเป็นเทรนด์ที่ริเริ่มทดลองใช้ได้ง่าย ยิ่งในองค์กรขนาดเล็กอาจจะใช้เพียงแค่เวอร์ชัน Community ซึ่งในหลายซอฟต์แวร์โอเพ่นซอร์สก็มักมีการต่อยอดเพื่อการค้า เช่น ปรับแต่งให้มีความสามารถระดับสูงที่เหมาะกับองค์กร เป็นต้น
จากความโดดเด่นเหล่านี้ Enterprise DB (EDB) จึงได้ต่อยอดให้ PostgreSQL มีฟีเจอร์สำหรับการทำงานระดับสูง เช่น
• Security – ตรวจสอบระดับ Session ได้ว่ามีกิจกรรมใดเกิดขึ้นในฐานข้อมูล ซึ่งเหนือกว่า PostgreSQL ธรรมดาที่ user ID อาจถูกแชร์กัน รวมถึงมีกลไกช่วยป้องกันการโจมตีแบบ SQL Injection และยังได้รับการรับรองจากกระทรวงการป้องกันของสหรัฐฯ และ FIPS 140-2 พร้อมเครื่องมือสำหรับช่วยดูแลข้อมูลให้เป็นไปตาม GDPR
• Enterprise Manager – ลูกค้าของ EDB PostgreSQL จะได้รับเครื่องมือช่วยเหลือมากมายจากเครื่องมือ Postgres Enterprise Manager เช่น Dashboard แสดงผลที่ปรับแต่งได้ แม้กระทั่งความสามารถคาดการณ์ความจุของพื้นที่จัดเก็บ ไปจนถึงมีส่วนช่วยวิเคราะห์และบริหารจัดการ Log ดูว่าในการทำงานมีประสิทธิภาพส่วนใดที่ติดขัด เป็นต้น
• Data Adapters – ทีมงาน EDB เป็นผู้พัฒนาหลักในการพัฒนาเรื่อง Foreign Data Wrapper (FDW) บนมาตรฐานของ SQL/MED โดยเป็นหัวหอกในการพัฒนา FDWs for MySQL, MongoDB และ Hadoop รวมถึงการเชื่อมต่อ PostgreSQL และ Oracle เข้าด้วยกันโดยไม่ต้องมีซอฟต์แวร์หรือฮาร์ดแวร์เสริม
• Migration Toolkit – มีเครื่องมือรองรับการย้ายค่ายจากฐานข้อมูลเดิมทั้งออนไลน์และออฟไลน์ โดยรองรับฐานข้อมูลยอดนิยมต่างๆ เช่น Oracle, Sybase, Microsoft SQL Server และ MySQL ซึ่งเครื่องมือ Migration ของ EDB Postgres นี้การันตีความสามารถรองรับ Stored Procedures และ PL/SQL ได้ซึ่งเหนือกว่าเครื่องมือทั่วไป
• Failover Manager – ผู้ใช้งาน EDB PostgreSQL มั่นใจได้ว่าการทำงานของระบบจะไม่มีสะดุดเพราะมีเครื่องมือทำ Failover โดยรองรับคลัสเตอร์ได้หลายกลุ่ม อีกทั้งยังทำได้อัตโนมัติทั้งไปและกลับ หรือการทำ Virtual IP และ Load Balancer
• Backup & Recover – สามารถทำการ Backup และกู้คืนข้อมูลได้จาก Local และ Remote มีการบีบอัดข้อมูลเพื่อลดพื้นที่ และรองรับการสำรองข้อมูลแบบ Incremental รวมถึงกู้คืนได้ใน Point-in-time และออกรายงานต่างๆ ได้

ข้อสังเกตสำคัญของ EDB PostgreSQL คือมีความสามารถในการทำงานที่สามารถแทน Oracle Database ได้อย่างยอดเยี่ยม แต่สิ่งหนึ่งที่ EDB PostgreSQL น่าสนใจกว่าก็คือ “เรื่องของค่าใช้จ่าย” ที่ประหยัดกว่าระบบของ Oracle อย่างเห็นได้ชัด ซึ่งเมื่อเทียบกันแล้วไม่ว่าจะเป็นต้นทุนการทำงาน หรือต้นทุนในแง่ของการใช้ MA ของระบบก็ประหยัดกว่า ส่งผลให้ผลองค์กรสามารถควบคุมค่าใช้จ่ายโดยรวมได้เป็นอย่างดี
ทั้งนี้ Stream มีทีมงานผู้เชี่ยวชาญที่ให้บริการโซลูชั่นของ EDB PostgreSQL สำหรับองค์กรด้วยเช่นกัน ซึ่งมีความพร้อมที่จะนำโซลูชันเข้าไปเสนอ ออกแบบ ทดสอบ สร้างระบบร่วมกับลูกค้าให้เหมาะสมกับองค์กร และดูแลต่อเนื่องหลังการติดตั้ง เรียกได้ว่าเรามีบริการดูแลตั้งแต่ต้นจนจบทุกขั้นตอน
สนใจสอบถามข้อมูลเพิ่มเติม
ปรึกษาฟรี!

ฝ่ายการตลาด
บริษัท สตรีม ไอ.ที. คอนซัลติ้ง จำกัด
Email: marketing@stream.co.th
Facebook: https://www.facebook.com/Streamitconsulting
Tel. 0-2679-2233

























{kind=link}
{kind=link}