ระบบที่คุณมองเห็นอยู่ตอนนี้ แค่ ‘ผิวเผิน’ หรือเข้าใจถึง “ต้นตอ” ที่แท้จริง ?
ปัจจุบันระบบ IT มีความซับซ้อนและเปลี่ยนแปลงอย่างรวดเร็ว ไม่ว่าจะเป็นทีม Development ทีม IT Operations หรือทีมดูแลระบบ ต่างก็เผชิญกับความท้าทายในการดูแลรักษาระบบให้ทำงานได้อย่างราบรื่นและมีประสิทธิภาพสูงสุด คำถามสำคัญที่เราต้องถามตัวเองคือ ระบบ Monitoring ที่เรามีอยู่ทุกวันนี้ ทำให้เรามองเห็นปัญหาแค่ผิวเผิน หรือช่วยให้เราเข้าใจปัญหาได้ลึกถึงต้นตออย่างแท้จริงกันแน่
หลายครั้งที่แม้จะมีระบบ Monitoring อยู่แล้ว แต่เมื่อเกิดปัญหาขึ้น ทีมยังคงใช้เวลาหลายชั่วโมงในการค้นหาสาเหตุที่แท้จริง (Root Cause) ไม่ได้ หรือเจอปัญหาเดิม ๆ ซ้ำซาก นั่นอาจเป็นสัญญาณว่าสิ่งที่คุณต้องการอาจไม่ใช่แค่ Monitoring แต่เป็น Observability
ทำความเข้าใจกับ Monitoring และ Observability
เพื่อให้เห็นภาพชัดเจนขึ้น เรามาทำความรู้จักกับสองคำนี้ให้ลึกซึ้งยิ่งขึ้น
Monitoring คือ การเฝ้าดูและวัดผลข้อมูลที่เรารู้จักและคาดการณ์ไว้ล่วงหน้า โดยจะตั้งค่า Dashboard หรือการแจ้งเตือน ตามตัวชี้วัดที่กำหนดไว้ เช่น การใช้งาน CPU, Memory หรือปริมาณ Traffic ที่เข้าสู่ระบบ
Observability คือ ความสามารถในการทำความเข้าใจสถานะภายในของระบบ จากข้อมูลที่ระบบส่งออกมา ไม่ว่าจะเป็น Logs, Metrics, และ Traces ซึ่งช่วยให้เราสามารถตั้งคำถามใหม่ ๆ ที่เราไม่เคยคาดคิดมาก่อน และตรวจสอบ วิเคราะห์ หาสาเหตุของปัญหาที่ไม่เคยเจอ (Unknown-Unknowns) ได้
สรุปง่าย ๆ คือ Monitoring บอกเราว่า มีอะไร ผิดปกติ แต่ Observability ช่วยให้เราเข้าใจว่า ทำไมถึงผิดปกติ
ปัญหาที่ทีม Dev / IT / Ops เจอบ่อย หากไม่มี Observability ที่ดี
เมื่อระบบขาด Observability ที่ดี ทีม Dev, IT, และ Operations มักจะติดอยู่ในวงจรการแก้ปัญหาที่ไม่มีประสิทธิภาพ ปัญหาที่เห็นได้ชัดที่สุดคือ การใช้เวลาในการค้นหาต้นตอของปัญหานานเกินไป (High MTTR) เพราะข้อมูลของแต่ละทีมถูกเก็บแยกส่วนกัน (Data Silos) ทำให้เมื่อเกิดเหตุการณ์ขึ้น ทุกคนต้องเสียเวลามากมายในการปะติดปะต่อเรื่องราวจากหลายแหล่งข้อมูล สถานการณ์เช่นนี้มักนำไปสู่ สงครามการกล่าวโทษ (Blame Game) ที่ทีม Dev และ Operations ต่างชี้ไปที่ส่วนที่ตนเองไม่ได้รับผิดชอบ เนื่องจากไม่มีข้อมูลกลางที่เชื่อมโยงกันเพื่อพิสูจน์สาเหตุที่แท้จริง โดยเฉพาะอย่างยิ่งในสถาปัตยกรรมสมัยใหม่ที่ซับซ้อนอย่าง Microservices หรือ Kubernetes การมองแค่ Metrics แยกส่วนนั้นไม่เพียงพอที่จะเข้าใจความสัมพันธ์และแก้ปัญหาที่ซับซ้อนได้เลย
ผลกระทบที่ตามมาไม่ได้จบแค่ภายในทีม แต่ยังส่งผลโดยตรงต่อธุรกิจและผู้ใช้งาน ระบบ Monitoring แบบดั้งเดิมที่ขาดความสามารถในการวิเคราะห์มักสร้างสิ่งที่เรียกว่า Alert Fatigue ทำให้ทีมเริ่มเมินเฉยและอาจพลาดการแจ้งเตือนที่วิกฤตจริงๆ ท้ายที่สุดแล้ว ปัญหาเหล่านี้หมายความว่าองค์กรจะทำงานในโหมด “ตั้งรับ” อยู่เสมอ ซึ่งกว่าจะตรวจพบความผิดปกติ ผู้ใช้งานก็ได้รับประสบการณ์ที่ย่ำแย่ไปแล้ว การขาดความสามารถในการมองเห็นปัญหาเชิงรุกเช่นนี้ไม่เพียงแต่ทำให้ธุรกิจหยุดชะงัก แต่ยังบั่นทอนความเชื่อมั่นของลูกค้าในระยะยาวอีกด้วย
WhaTap ก้าวข้ามขีดจำกัดของ APM สู่ Observability ที่แท้จริง
เมื่อการมองเห็นระบบแค่ผิวเผินอาจไม่เพียงพอ WhaTap จึงถูกออกแบบมาเพื่อเป็นมากกว่าเครื่องมือ APM ทั่วไป แต่เป็นแพลตฟอร์ม Observability แบบครบวงจรที่ช่วยให้คุณเข้าใจปัญหาได้ลึกถึงต้นตอ เบื้องหลังความสามารถอันทรงพลังของแพลตฟอร์มนี้คือ WhaTap Labs Inc. บริษัทผู้เชี่ยวชาญด้าน IT Monitoring & Analysis จากกรุงโซล ประเทศเกาหลีใต้ ที่ก่อตั้งขึ้นในปี 2015 ด้วยวิสัยทัศน์ที่ต้องการสร้างเครื่องมือ Observability ที่ครบวงจรทำให้ WhaTap Labs เติบโตได้อย่างรวดเร็วจนกลายเป็นผู้นำในอุตสาหกรรม B2B SaaS Software ที่มีความโดดเด่นหลากหลาย
หัวใจสำคัญของ WhaTap คือ Real-Time Monitoring ที่ช่วยให้คุณเห็นความผิดปกติได้ทันทีผ่าน Dashboard และ Infographics ที่สวยงาม ไม่เพียงเท่านั้น WhaTap ยังเปลี่ยนข้อมูลที่ซับซ้อนให้กลายเป็น Response Time Distribution (Heatmap) ที่เข้าใจง่าย ช่วยให้คุณเห็นภาพรวมประสิทธิภาพและมองเห็นปัญหาที่ซ่อนอยู่ได้อย่างรวดเร็ว
จุดเด่นที่ทำให้ WhaTap แตกต่าง ด้วยความสามารถในการวิเคราะห์เชิงลึกได้ทันที โดยไม่จำเป็นต้องรอให้ปัญหาเกิดซ้ำเพื่อใช้ในการวิเคราะห์ ด้วยฟีเจอร์ Active Transaction ที่บันทึก Snapshot ของ Transaction ทุก ๆ 10 วินาที ทำให้เมื่อเจอ Transaction ที่ช้า คุณสามารถเจาะลึกไปอีกขั้นด้วย Analysis on Active Stack ที่บันทึกการทำงานของ Thread อย่างต่อเนื่อง ช่วยให้ทีมสามารถชี้ชัดถึงต้นตอของความล่าช้าได้ถึงระดับ Code หรือ Module ที่มีปัญหาได้อย่างแม่นยำและทันท่วงที
Key Feature WhaTap
Real-time Monitoring: ตรวจจับความผิดปกติและปัญหาของแอปพลิเคชัน เซิร์ฟเวอร์ ฐานข้อมูล และโครงสร้างพื้นฐานอื่น ๆ ได้ทันที ผ่าน Dashboard ที่อัปเดตสถานะ Transaction ทั้งที่กำลังดำเนินการและที่เสร็จสิ้น พร้อมแสดงภาพรวมด้วย Infographics
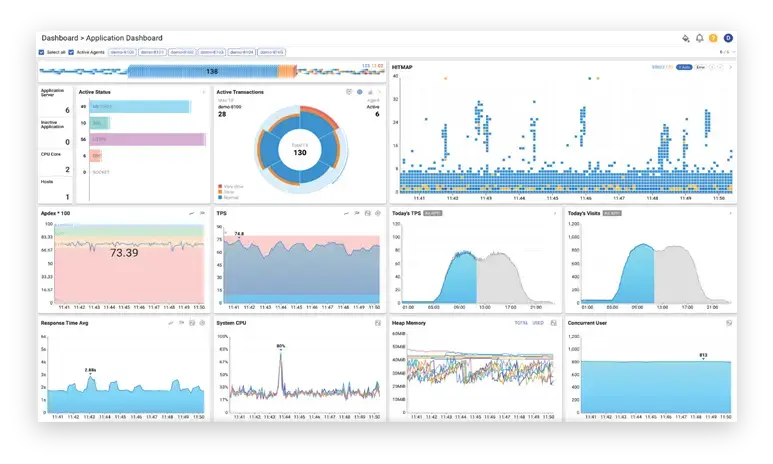
Active Transaction: ตรวจสอบ Transaction ที่กำลังดำเนินการอยู่ รวมถึง Stack ได้ โดย WhaTap จะบันทึก Snapshot ของ Transaction ทุก 10 วินาที และข้อมูล Stack สำหรับ Transaction ที่ใช้เวลาตอบสนองนาน ทำให้วิเคราะห์สาเหตุได้ทันทีโดยไม่ต้องจำลองสถานการณ์
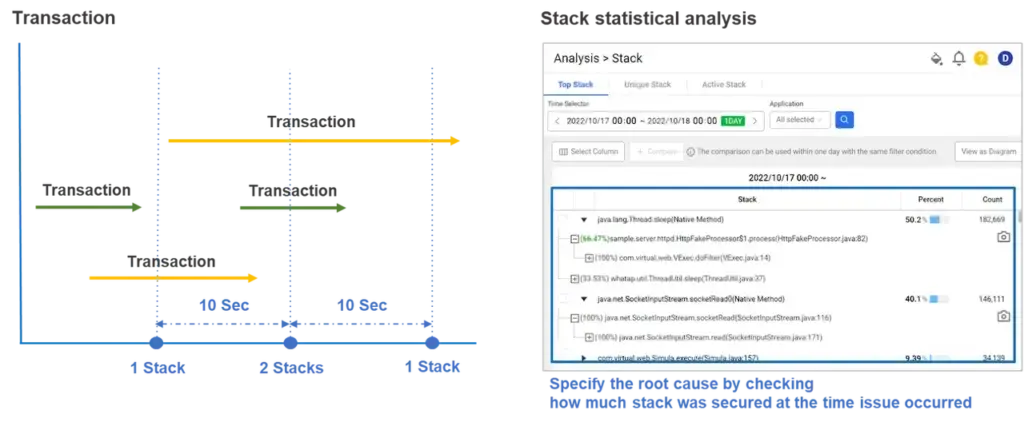
Analysis on Active Stack / Top Stack: ตรวจสอบสาเหตุได้อย่างรวดเร็ว ด้วยการบันทึก Stack ของ Thread ทุก 10 วินาทีสำหรับ Transaction ที่กำลังดำเนินการ และแปลงความสัมพันธ์การเรียกใช้ใน Stack เป็นข้อมูลอัตราส่วนระหว่าง Modules
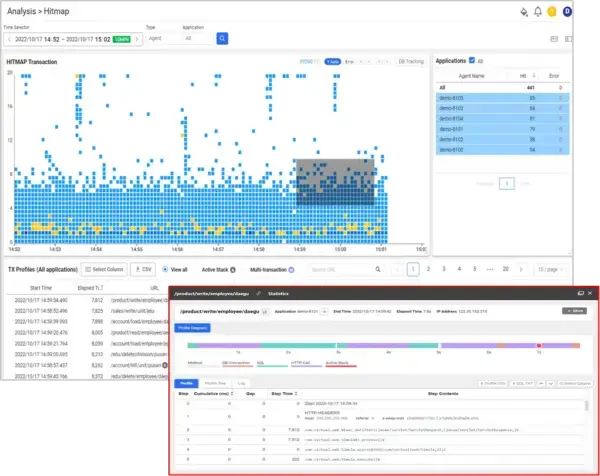
Response Time Distribution (Hitmap): แสดงการกระจายตัวของเวลาตอบสนองของ Transaction ทุก 5 นาที ช่วยให้เห็นภาพรวมประสิทธิภาพ และสามารถเลือกธุรกรรมที่ช้าเพื่อวิเคราะห์รายละเอียดได้
Stream I.T. Consulting ในฐานะ Official Partner ของ WhaTap Labs ในประเทศไทย อย่างเป็นทางการ ด้วยประสบการณ์และความเชี่ยวชาญกว่า 27 ปี สตรีมฯ เป็นที่ปรึกษาด้านดิจิทัลชั้นนำของประเทศไทย พร้อมให้คำปรึกษาและออกแบบโซลูชันที่ครอบคลุม เสริมศักยภาพธุรกิจของคุณด้วย WhaTap เครื่องมือสำคัญที่ช่วยยกระดับประสิทธิภาพของระบบและประสบการณ์ของผู้ใช้งานให้ดีขึ้น ด้วยความสามารถด้าน Monitoring และ Observability ที่ครบวงจร